【折腾】记录一次CentOS的检修
Last updated on June 18, 2024 pm
成果展示
好像在线时间4天也不算什么成果展示了 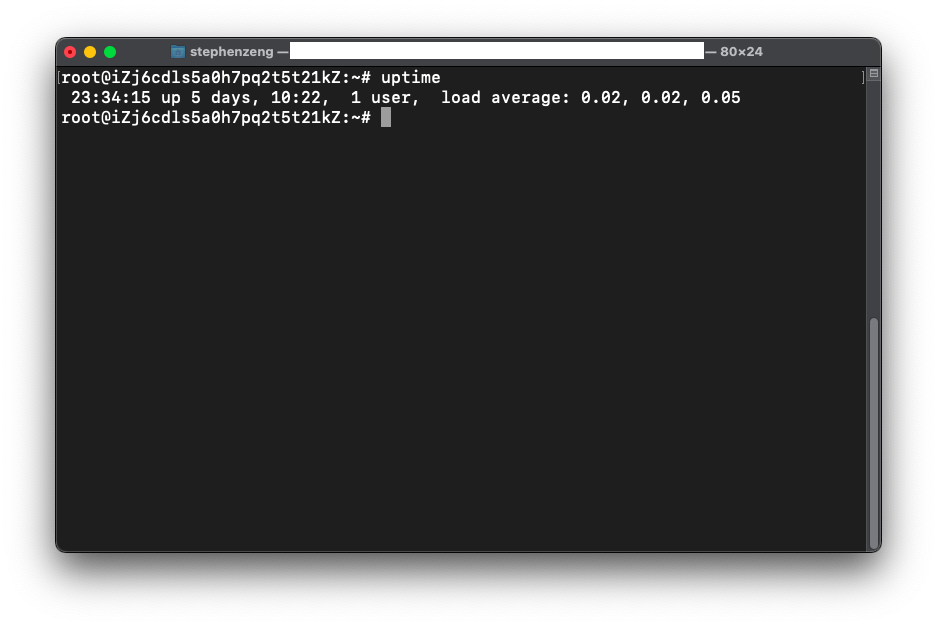
故障形式
其实很简单,这家伙隔三差五给我宕机,就ping都ping不通的那一种。ping.chinaz.com全红 :shock:
故障排查
原因分析
我的小小阿里云是2H1G(没钱没办法 :sad: ),负载量极高,上面跑了两个WP,一个Typecho和几个轻量PHP,还有一堆非PHP网站,所以首先想到的就是由于负载过高导致的宕机。
1 | |
(对,没错,因为内核不能升级,但是又想要网络稍微好一点,所以用的腾讯的TCPA内核) 所以,想到的第一点就是先把两个WP关了(耗能大户),看看稳不稳得住。结果确实,稳住了一个星期没有宕机。到这里我以为我只要简简单单把高负载应用移出去就好了,但是请看后文
移植WP
WZB好像说现在的人都不用WP,都跑过去用Hexo了???
白嫖Vercel?
本来想着可以白嫖Vercel的,因为Vercel不是开放了php Runtime嘛,结果死活说我的php包太大了 :evil: (妈妈省的) 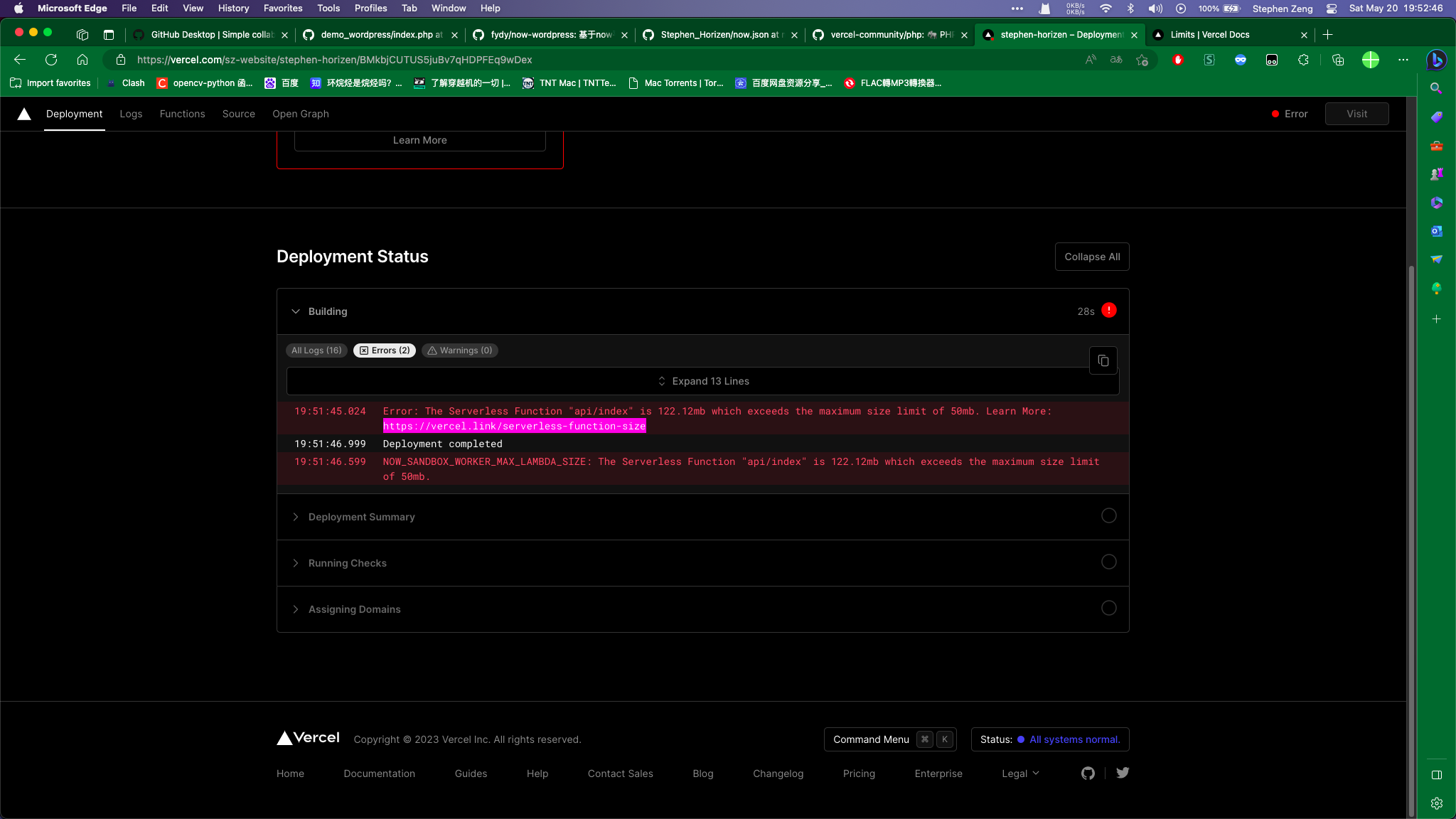 然后就好像白嫖失败了,不过没关系,作为羊毛党,绝对不会罢休!
然后就好像白嫖失败了,不过没关系,作为羊毛党,绝对不会罢休!
转战AWS
说实话我还在Azure和AWS之间徘徊到底要白嫖哪一个,但是最后看tb上AWS的信用卡认证比Azure要便宜CNY10,然后就果断AWS :mrgreen: 。 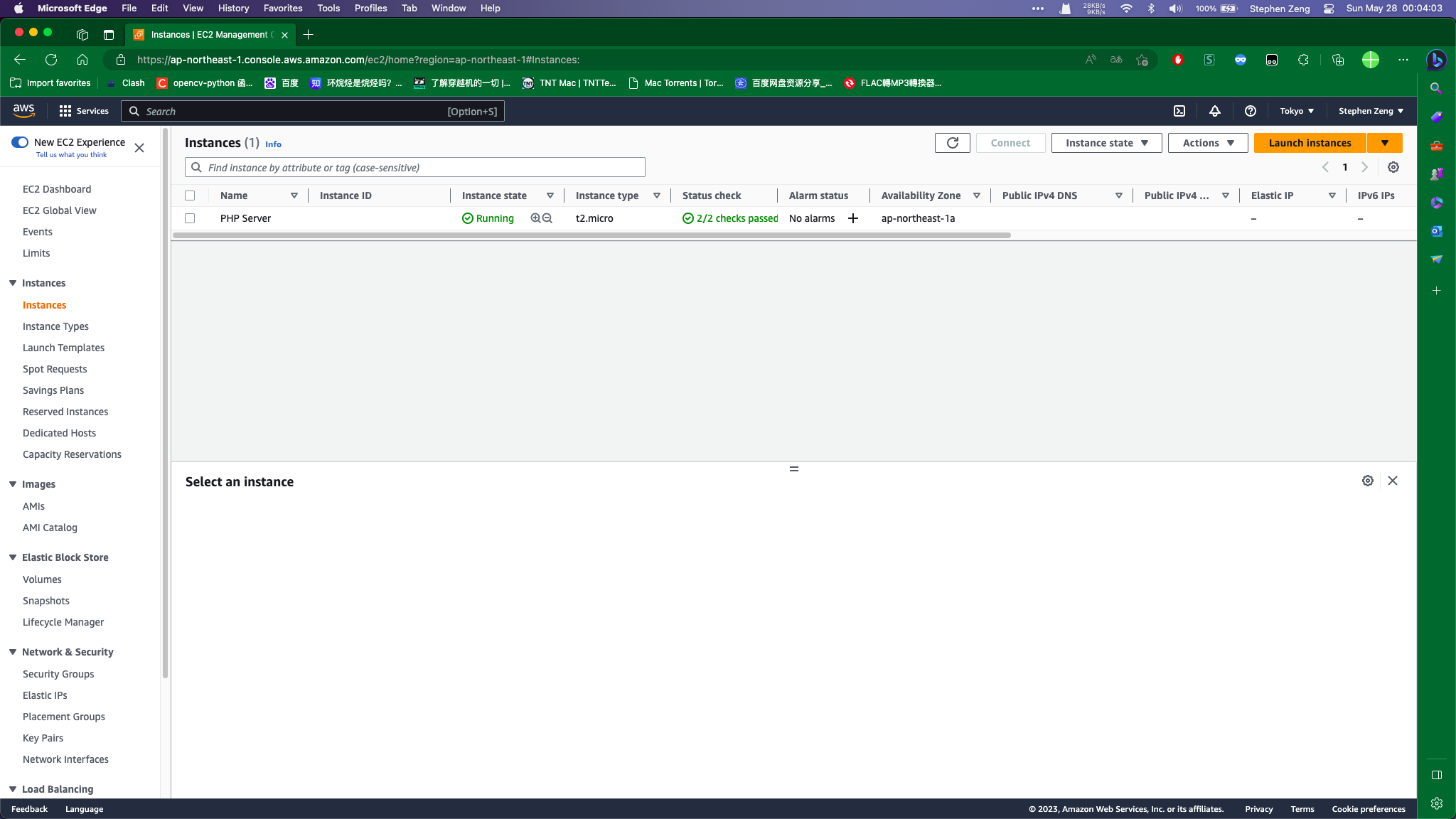 然后就把两个WP丢到这台AWS的小鸡上跑,这样不就可以降低负载了嘛。至于AWS网络不行,没关系,我可以阿里云反代AWS,然后就解决问题了。至于香港到日本的网络,其实还好,基本上阿里云和亚马逊的网络是直连的,也就是从一个内网走到另一个内网
然后就把两个WP丢到这台AWS的小鸡上跑,这样不就可以降低负载了嘛。至于AWS网络不行,没关系,我可以阿里云反代AWS,然后就解决问题了。至于香港到日本的网络,其实还好,基本上阿里云和亚马逊的网络是直连的,也就是从一个内网走到另一个内网 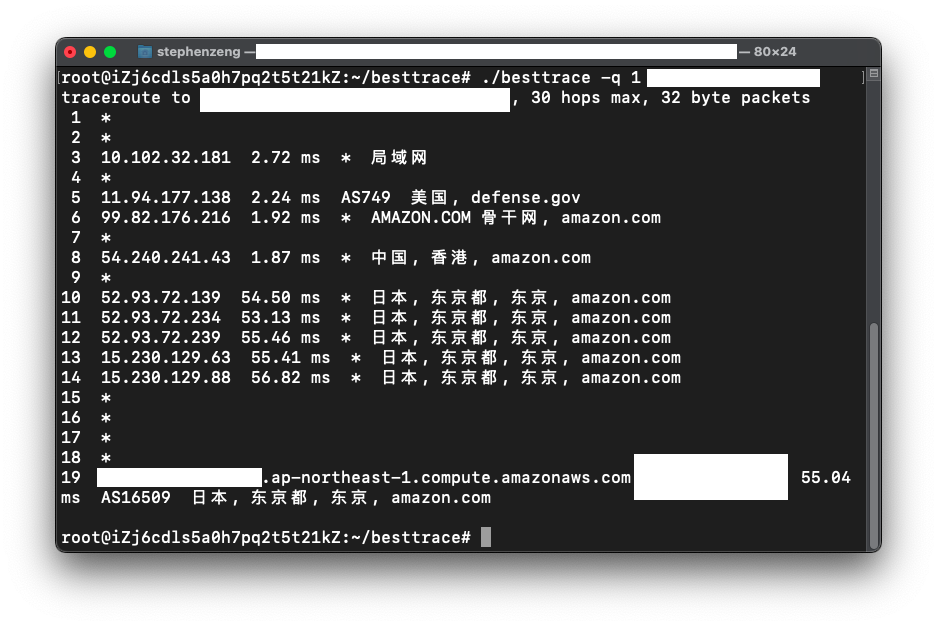 所以两台服务器之间的网络连接就基本上不存在问题了。
所以两台服务器之间的网络连接就基本上不存在问题了。
新问题?
对,没错,当我自信满满地以为问题就此解决了之后,阿里云又不争气地倒下了,,, :eek: (没有截图)。这就说明了之前把WP关闭之后坚持了一个星期是纯纯的偶然事件,实际问题还是没有解决。
寻找问题
好好好,逼得我去看日志是吧 :roll: ,日志目录是/var/log,我们只需要查看其中的message文件就好。首先我们得确定宕机时间,这里可以查看阿里云后台,结果发现只有CPU占用率是正常的,这也证明了并不存在外接网络攻击的可能。

好,发现在4点半差不多这个时候的CPU占用率突然就上去了,我们就可以直接查看这个时间附近的日志
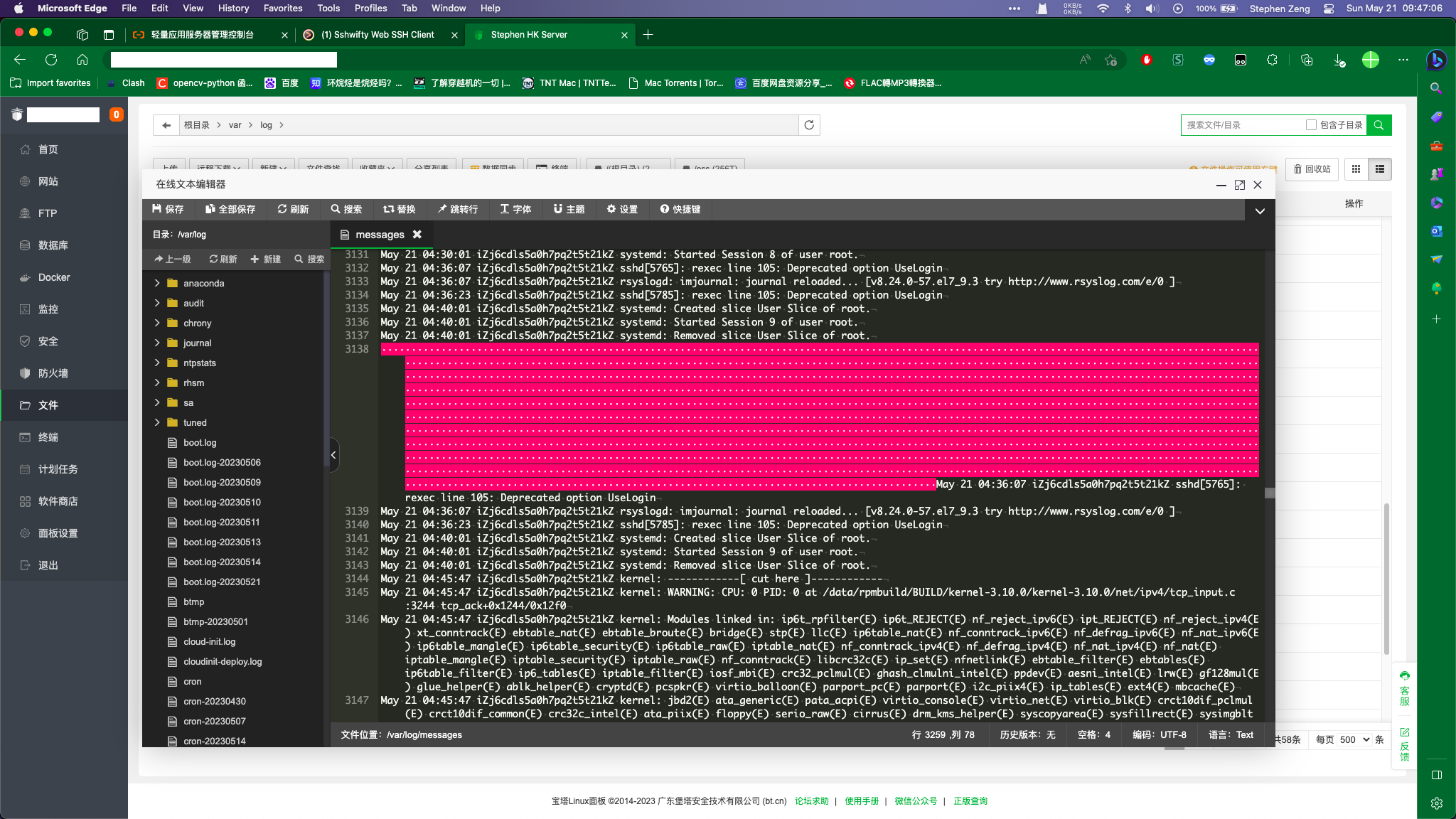
这里貌似发生了点什么事情,但是又什么都看不出来。接着往下找,,,
猎杀时刻
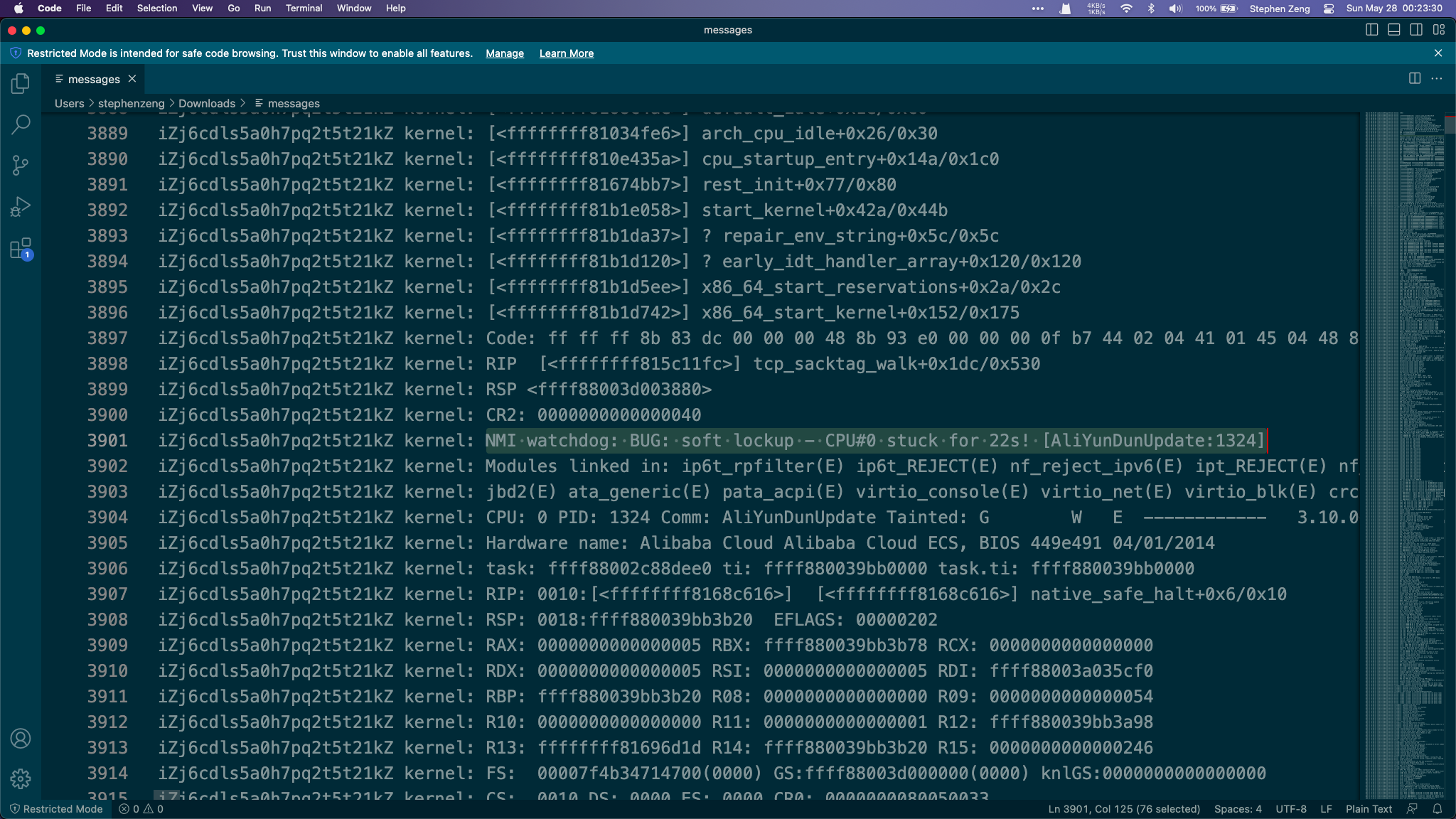 看看我发现了什么! :wink: 原来是阿里云盾在搞鬼!也难怪了,更新都能卡死,不晓得再搞什么鬼。也有可能是腾讯的内核不兼容阿里云盾?(瞎脚本乱说的,别当真 :!: )再来欣赏一下阿里云盾的杰作:
看看我发现了什么! :wink: 原来是阿里云盾在搞鬼!也难怪了,更新都能卡死,不晓得再搞什么鬼。也有可能是腾讯的内核不兼容阿里云盾?(瞎脚本乱说的,别当真 :!: )再来欣赏一下阿里云盾的杰作:
1 | |
就是说这是真的nb
解释一下Soft Lock,这是一种系统锁死的方式,大概工作原理就是检测到一个进程占用CPU时间过长且无法执行其他命令的时候就会将CPU锁死,一般来说重启就可以解决问题了。 给一下Linux Kernel官方的解释 https://docs.kernel.org/admin-guide/lockup-watchdogs.html
所以说理论上来说,我们只需把阿里云盾删了就好了。
问题解决?
然而并没有。。。当我再一次以为问题解决的时候,Diwanul告诉我WP又™寄了。好家伙,我再一看日志,看门狗又给锁了。然而,这一次锁死的进程不肯定不是阿里云盾(我都给删了难不成还复活了?),变成了,,,系统日志系统?????
1 | |
我们把日志系统也给删了吧 很明显,这个时候我们就只能对看门狗下手了。
最后猎杀
仔细查看,发现时间都是20s,这是因为看门狗的默认时间允许范围就是20s,我们可以尝试着把时间允许范围调宽松一点。
1 | |
这里的30就是30s的意思,然后重启。问题应该解决。
总结
首先保存快照!! 寒假的时候服务器都是活得好好的,阿里云香港C区散热炸了那次不算,因为不是我的原因。然后到开学的时候就疯狂宕机了。这是不是侧面反映出其实阿里云正在限制轻量级服务器的性能,以便和ECS拉开差距?毕竟看门狗锁死系统的根本原因还是性能问题,如果CPU算力够的话起码不会日志系统都可以导致锁死。当然,也不能排除确实是项目跑得太多了,本来配置就拉胯。不管怎么样,事情应该算是解决了,这一次排查也相对简单。 Peace out :twisted: